Redis persistence and high availability
I was recently at a presales event in Kuala Lumpur where they run my conference app (I will talk about the app in detail in a later post because it has played a key role in the Pied Piper program). One of my colleagues asked me about the backend the app uses. When I explained it was Redis he said that Redis doesn't have data persistent as is an in-memory database. There are two misconceptions about Redis:









- Redis uses key-value
- Redis is in-memory, therefore I can loose my data
The first one is correct, but as we explained in the Redis article, the value side can be much more than just a "value", it can also take the form of a list, a set, a hash (which is essentially a dictionary) and more. So yes, you cannot do things a relational database can do, but with those 3 structures alone there are lots of use cases you can do ... and before I forget it is VERY fast.

The second one is not true. When we looked at the different plans available in Pivotal Web Services (which are essentially Redislabs offerings) all the paid plans included various data protection and availability features:
- Replication - This will carve 2 in-memory instances and setup replication between them. The second one automatically fails over if the first one crashes. These 2 copies live in different nodes in the cluster as can be seen in the previous screenshot and if designed correctly your DB will withstand full rack failure. When replicating locally you can set it to be synchronous so that there is no data loss. Replication can also be configured between remote locations
- Persistence. This setting persists the in-memory contents to disk at regular intervals, more on this later
- Backups. Daily backups. You can trigger a backup at any time manually as well
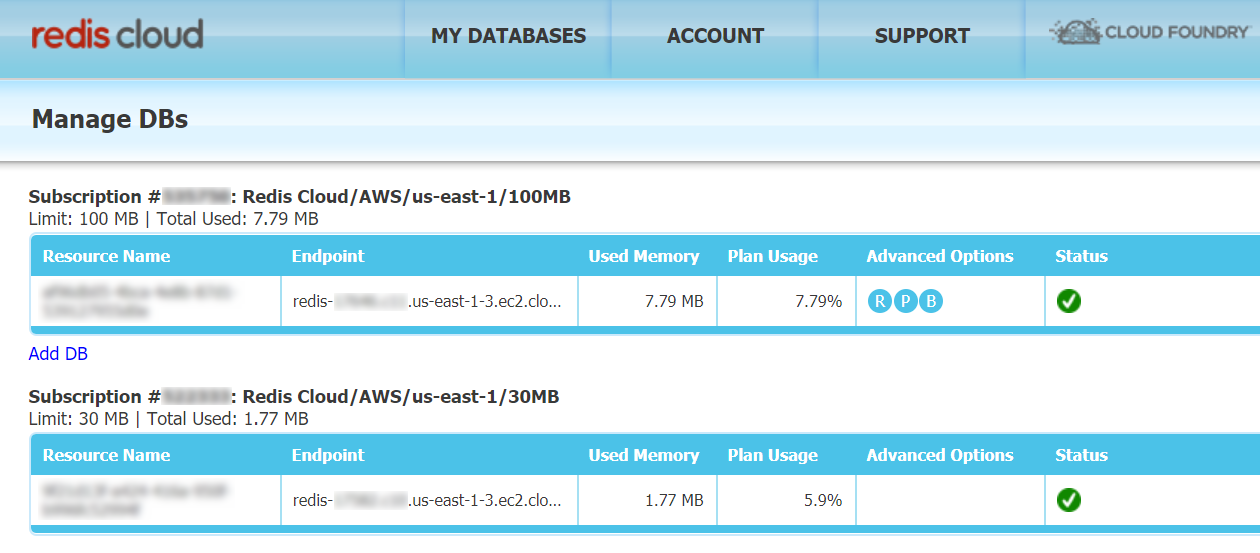
In the screenshot above you can see there are 2 databases in this account. The one at the bottom is a free tier plan, which allows for up to 30MB and no resilience features. On the other hand the top one is the 100MB ($10/month). I got this one for a month to run the production app. In the advanced options you can see 'R P B', which stand for Replication, Persistence and Backup. Since I selected Replication, the overall storage capacity of the instance is 50MB. During my testing I figured out that 50MB should be plenty. As you can see I only ended up needing 7.79MB.
The following screenshot shows the Edit menu for the production instance. You can see the Replication setting enabled as well as the different options for Data Persistence. The default setting "fsync every 1 sec". So could I loose data? yes up to 1 sec worth. That is pretty good for most use cases.

Finally the following screenshot shows the last few backups that the plan has done automatically for me. I click on the latest one and it automatically downloads to my laptop.

The way I like to work is to use the free tier for development, and then since the deployments I do typically don't last more than a few days I get one of the small paid Redis instances to benefit from the increased capacity, amount of connections and the 3 data protection features we have covered.
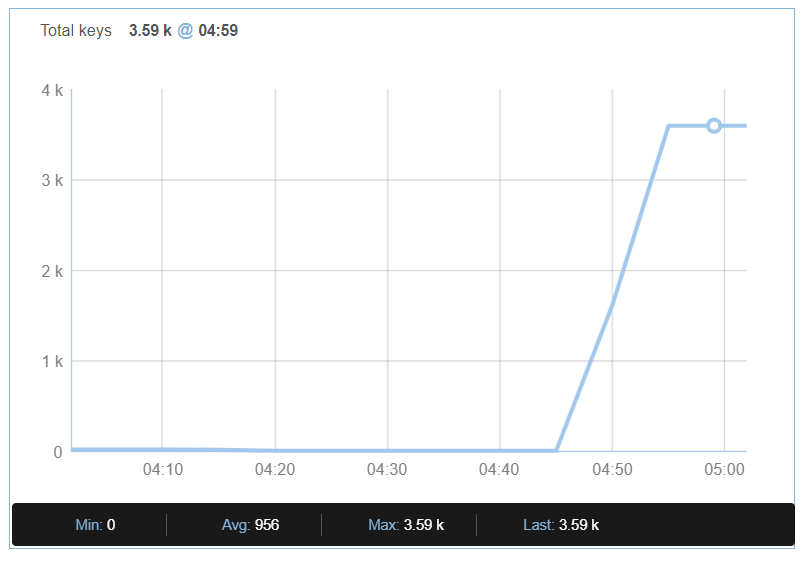
Now that the event is over I will tear down the production instance so that I don't get charged in subsequent months, but I would like to keep the data my app generated and use it for future functionality I am planning. As you can see the 350 users that participated in the event generated a total of 3590 keys in the database and the latency was pretty good all along.

Now when I go to the development free-tier database I can see and "Import" button at the bottom. I click on it and I get the following warning message.

Importing a dataset erases the existing data. That's fine by me so I click "Yes" and I am given the possibility of importing the database in a number of ways. First I try putting the hostname, port and password of the production database, but I get an error that it couldn't connect to it ... a real pity, as this would be the most straight-forward method. I think Redis Cloud should make this seamless by offering a drop-down menu to select other databases in the same space.

Anyway I don't despair because there was still plenty of other methods to try. See below:

I try the FTP method next by using an FTP server we have at work with no luck. Maybe the problem here is the security in our FTP. Next I upload the backup to S3 and use:
https://{mybucket}.s3.amazonaws.com/{my_filename}.rdb.gz
and it works! The only thing left is to go to the app to change the bindings from the Production instance to the Development one, and I am done. As you can see here my 3590 keys are available in the new database:
In conclusion, Redis is an in-memory key-value store, but if you leverage its persistence features, it is a great choice for lots of use cases ... and fast ... and simple

Comments
Post a Comment